Comparing Two Sets of Data in OpenRefine
- Former user (Deleted)
- Kristen Wilson
Sometimes you want to compare a list of journals in a Refine project to another (for example, you might want to compare a new list from a content provider or publisher, to a list that has previously been loaded into GOKb).
The exact approach to comparing a list in Refine to other data sources depends on what data you have, and what formats are available. The two main options are:
- Compare one Refine project to another Refine project
- Look up lines in a Refine project against a web site or API
Comparing two Refine projects
The simplest way to compare two lists of journals from different sources is to first get both lists into Refine and to use the 'cross' function to lookup values in common or missing between the two projects. To do this the two projects will need to have at least one column containing the same type of data. Such columns do not have to be named the same but do need to contain the same information - for example ISSN. The method described below relies of matching values between two Refine projects, so values that are likely to be consistent are the most useful. ISSN, eISSN, DOI and other identifiers are useful. When dealing with KBART data the title_id or title_url columns can prove useful when you are comparing two files from the same content provider, but not when dealing with different content providers.
Titles can be used for matching, but usually this requires some work to try to standardise the titles to avoid small differences between titles (e.g. '&' vs 'and') before carrying out the comparison.
It is possible to use several different 'match' data points in a single comparison.
The tools available in Refine do not, unfortunately, allow you to do a complete comparison in one step. To completely compare two lists (say ListA and ListB), you will first need to work from ListA and lookup titles that are in ListA but not in ListB, and then secondly work from ListB and lookup titles that are in ListB but not in ListA. However, you may not need to compare in both directions in all cases.
| ListA | Comparison direction | ListB |
|---|---|---|
| Journal 1 | -------> | Not present |
| Journal 2 | <------> | Journal 2 |
| Journal 3 | <------> | Journal 3 |
| Journal 4 | <------> | Journal 4 |
| Not present | <------- | Journal 5 |
Doing a lookup from ListA to ListB would tell you that Journal 1 was missing from ListB, but would not be able to tell you about Journal 5, and vice versa.
Simple comparison example
- Two lists of journals have been used to create Refine projects (ListA and ListB), and both projects have been edited so they contain a column named 'title.identifier.issn' containing ISSNs for the journals in the list
- Open ListA, click the 'title.identifier.issn' column header and choose 'Edit Column' -> 'Add column based on this column ...' from the dropdown menu
- In the 'New column name' box enter a column name such as "ListB Comparison" (any name will do)
- In the 'Expression' box enter the text:
cell.cross("ListB","title.identifier.issn").length()
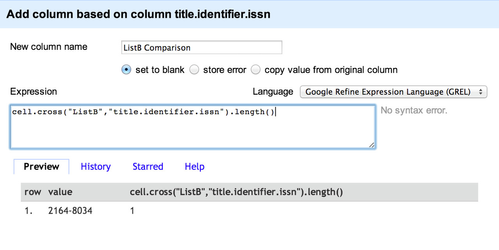
- Click 'OK'. This will populate a new column with a number representing the number of matching lines found in ListB
- If the "ListB Comparison" column contains a zero (0) then no match has been found
- If the "ListB Comparison" column contains a one (1) then a single match has been found
- If the "ListB Comparison" column contains a two (2) then two matches have been found
- etc.
- Facet on the new 'ListB Comparison' column to find those lines in ListA that do not appear in ListB (a zero in the column)
- To identify journals that are in ListB but not in ListA, the same process is carried out starting with the 'title.identifier.issn' column in the 'ListB' project
Comparison with titles example
- Two lists of journals have been used to create Refine projects (ListA and ListB), and both projects have been edited so they contain a column named 'title.identifier.issn' containing ISSNs and a column named 'PublicationTitle' containing journal titles
- Open ListA, click the 'title.identifier.issn' column header and choose 'Edit Column' -> 'Add column based on this column ...' from the dropdown menu
- In the 'New column name' box enter a column name such as "ListB Comparison" (any name will do)
- In the 'Expression' box enter the text:
forEach(cell.cross("ListB","title.identifier.issn"),r,r.cells.PublicationTitle.value).join("|")
- Click 'OK'. This will populate a new column with all matching titles found for the relevant ISSN, with a 'pipe' character | between each title. The pipe character was chosen simply because it is unlikely to appear in any journal title. Some other separator by amending the expression above. If there is no match the relevant cell will be blank
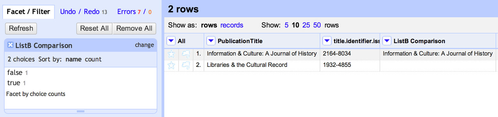
- To find all the rows in ListA which found no match in ListB, click on the column header drop down in the new "ListB Comparison" column and choose 'Facet' -> 'Customized Facets' -> 'Facet by blank'
- In the resulting Facet those rows found by the 'true' facet (i.e. there is a blank in the column) are the ones which found no match
- To find all the rows in ListA which found multiple matches in ListB, click on the column header drop down in the new "ListB Comparison" column and choose 'Text filter' and then type the pipe character '|' into the text filter box
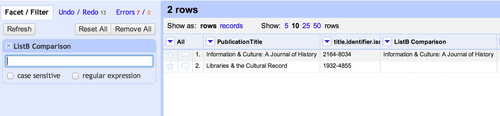
Using this 'title lookup' approach allows you to ensure that the lines that match on ISSN are indeed referring to the same journal.
When comparing a previously edited list from a content provider, with a new list from the same content provider, discrepancies between the lists can often be due to the previously edited list having been modified to contain additional lines to reflect title histories. In this case it is useful to use the technique described above to bring in any information on title history from the other list this can be done using an expression such as:
forEach(cell.cross("ListB","title.identifier.issn"),r,r.cells.CoverageNotes.value).join("|")Comparison using iterative matching example
While ISSN and eISSN are good match points due to their consistency and prevalence in journal lists, it is not unusual in a single list for some titles to have an ISSN but no eISSN and vice-versa. It is also not unusual for some titles to have neither an ISSN or an eISSN. Because the 'cross' lookup relies on finding matches, if in one list Journal Title A only has an ISSN, and in the other list Journal Title A only has an eISSN (in a different column) then a comparison would suggest (falsely) that Journal Title A was missing from the second list. Therefor it is sometimes useful to run matches for several columns across the two lists before looking at the outcome of the comparison.
This example shows how you can use several different match points one after another.
- Two lists of journals have been used to create Refine projects (ListA and ListB), and both projects have been edited so they contain a column named 'title.identifier.issn' containing ISSNs and a column named 'title.identifier.eissn' containing eISSNs and a column named 'PublicationTitle' containing journal titles
- Open ListA, click the 'title.identifier.issn' column header and choose 'Edit Column' -> 'Add column based on this column ...' from the dropdown menu
- In the 'New column name' box enter a column name such as "ListB Comparison" (any name will do)
- In the 'Expression' box enter the text:
cell.cross("ListB","title.identifier.issn").length()
- Click 'OK'. This will populate a new column with a number representing the number of matching lines found in ListB
- Facet on the new 'ListB Comparison' column to find those lines in ListA that do not appear in ListB (a zero in the column) based on a title.identifier.issn match, and select the 'true' facet to ensure you have filtered the list to only those for which this first step did not find a match
- Click on the column header of the new 'ListB Comparison' column and choose 'Edit Cells' -> 'Transform ...'
- In the 'Expression' box enter the text:
- cells["title.identifier.eissn"].cross("ListB","title.identifier.eissn").length()
- When you click 'OK', this will use the contents of the title.identifier.eissn column in ListA to check for matches in the title.identifier.eissn column in ListB
Normalise titles to do comparison
The above examples use ISSN to lookup between two sheets because generally ISSNs are used consistently. While it is sometimes necessary to do some small changes to ensure consistency between ISSNs (e.g. adding hyphens if they are missing, or ensuring both sets of ISSNs use uppercase 'X' - both easily fixed via Quick Fix Transformations), generally you can use ISSNs for comparisons without a lot of effort. However sometimes you want to compare using title strings, and as these vary much more between different journal lists simply using the title 'as is' can lead to you missing matches.
To improve title matching you can create a 'normalised' form of the title in each of the projects you are comparing which will help you get better matching on titles. First create a 'normalised title' column in each sheet:
- Click on the PublicationTitle column header and choose 'Edit column' -> 'Add column based on this column...'
- In the 'New column name' enter 'Normalised title' (or similar)
- In the 'Expression' box just enter 'value' (this should appear by default
- Click OK - this will duplicate the PublicationTitle column under the heading 'Normalised title'
You now need to apply various transformations to the 'Normalised title' column to modify the title string. A number of useful transformations are listed separately in the column below for clarity, and they can be applied individually or together. Generally you'll want to apply all of them to get to the best 'Normalised title'. The danger with 'normalising' the title is that some changes could result in two different titles appearing the same. The transformations below are reasonably conservative, but it is always possible to have two journals with the same name even without normalisation, and using the normalisation processes below just slightly increase chances of false positive matches.
| Description | Transformation | Notes |
|---|---|---|
| '&' vs 'and' | value.replace("&","and") | Replaces all occurrences of '&' with word 'and' |
| "The journal" vs "Journal" | value.match("^(The )?(.*)")[1] | If the title starts with 'The ' remove this and use just the remainder of the title |
| Remove special character, case and word order issues | value.fingerprint() | The 'fingerprint' functions does a range of things in one go:
|
Further normalisation processes can be added as appropriate, or a more aggressive approach could be taken (e.g. remove all occurrences of 'the' rather than only if the title begins with 'the').
Since Refine allows you to chain together transformations, all of these transformations can be carried out in a single line of code:
value.replace("&","and").match("^(The )?(.*)")[1].fingerprint()You can apply this when using the 'Add column based on this column...' function to create the normalised title column containing a normalised title in one operation. Once you have done this in your first project, you'll want to do the same in your second project (just cut and paste the same code in the second project, or use the 'Extract' and 'Apply' mechanisms)
When you've created both 'Normalised Title' columns you can then use the 'cross' function as described in the examples above to compare the two lists based on title.
Further examples
To-do
- screencast of lookups using the 'cross' function
- Looking up via an API
Operated as a Community Resource by the Open Library Foundation